AI Is Not a PhD — It Shines When You Don't Know, and Crumbles When You Do
AI looks like a genius only when you lack the expertise to evaluate it. The quality of AI output scales with the user's judgment. Here's the operator's framework for the difference, and how to extract 10x from a tool that is neither good nor bad on its own.
Column · Operator Notes from Zero Human Studio
AI Is Not a PhD
A sentence from a lunch table: "AI looks like a PhD in every field you don't know — and a freshman in every field you do." That single observation is the starting point of every practical AI conversation. The tool is the same. It pretends to be smart the same way. The only difference is the operator.
Key Takeaways
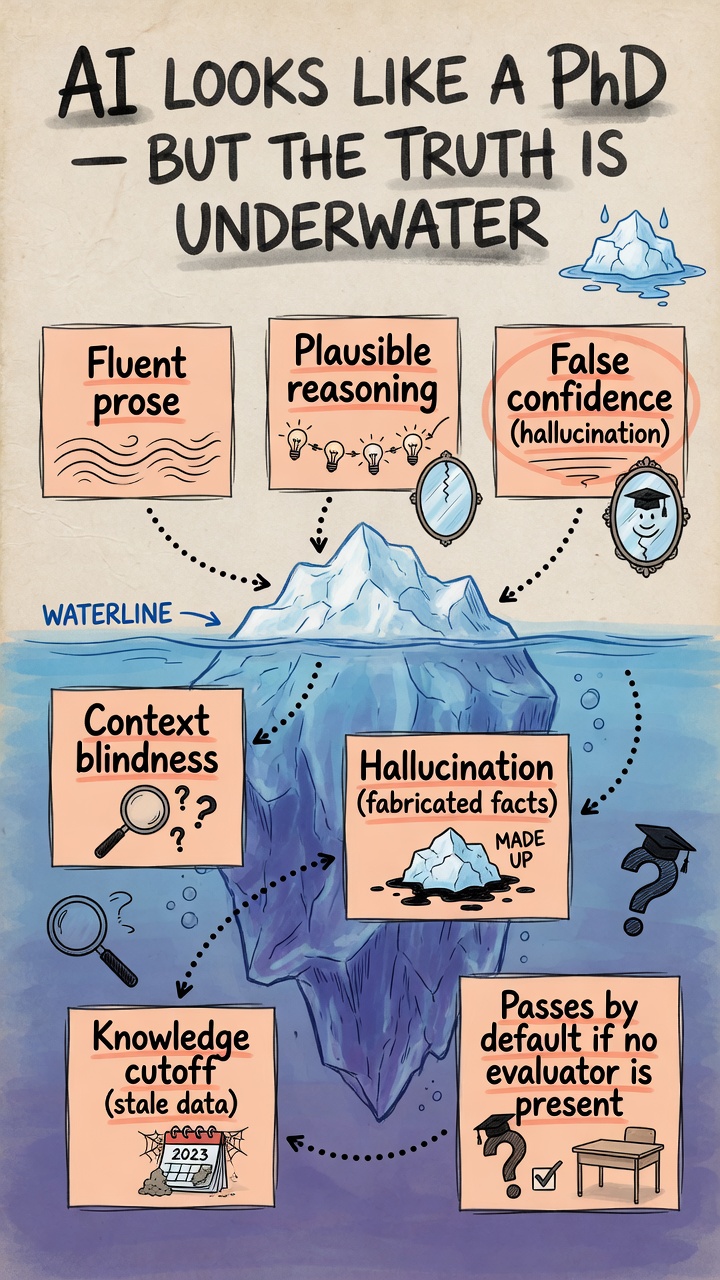
1. AI quality scales with the user's judgment
You can only use AI properly when you can evaluate its output. For a user without that capacity, AI is a confident liar.
2. The illusion of brilliance in unfamiliar territory
You don't know enough to notice the small errors. The polished surface becomes indistinguishable from correctness. The PhD effect is, in fact, your own ignorance.
3. The collapse in familiar territory
In your own field, the gaps are obvious. Context blindness, stale references, confidently wrong phrasing. The model is a mirror, not a mentor.
4. AI is a multiplier, not a substitute
Zero judgment times AI is still zero. Strong judgment times AI is 200, 500, sometimes 1000. The variable that matters is the human.
The Lunch Table Illusion — Why AI Looks Like a PhD When You Don't Know the Field
We see the same scene almost every day. A colleague has a thirty-minute conversation with an AI about quantum computing, drug discovery, aerospace engineering, or fourteenth-century Persian literature — and walks away saying, "This thing is basically a PhD." Polished vocabulary. Plausible causal chains. Names of figures they have never encountered. The conclusion: AI has genuinely become intelligent.
It has not. That colleague doesn't know quantum computing. They don't know the canonical roster of Persian literary scholars. So every plausible-sounding name and every well-structured sentence registers as "authoritative truth." A human cognitive firewall — the automatic alarm that says "this is suspicious, verify" — needs at least some substrate to fire. Where that substrate is zero, AI holds unlimited authority.
On top of that, large language models are trained to be remarkably fluent. Sentence structure, tone, word choice, logical transitions — all of it is optimized to mimic competent human writing. What we end up seeing is not the accuracy of the content but the fluency of the expression. If you can't separate the two, AI remains a PhD forever — for as long as you don't know the field.
The Expert's Frustration — Why AI Is So Painfully Shallow in the Fields You Know
Then the same person turns to AI in the field they have practiced for a decade. They ask for marketing copy. For legal review. For a data pipeline. The output is — to be honest — devastating. The surface is fine. The core is hollow. Details are missing, context is ignored, industry-current examples lag by six months, and the model confidently suggests the exact phrasing the company has explicitly banned.
Why does this happen? The answer is straightforward. An LLM is a model that predicts the next token from a statistical distribution of training data. It is not a system that verifies facts or composes correct answers in new contexts. So it cannot distinguish a "common and correct" pattern from a "common and wrong" one. Only the user can. And only when the user can, the output becomes meaningful.
Only the person who can ask "is this wrong?" can use AI properly. That ability comes from expertise.
In other words, AI looks shallow in your field not because AI has gotten worse, but because a baseline of "what shallow looks like" has formed in your head. Without that baseline, the same shallowness passes as sophistication. Perhaps what we forget the moment we call AI a "tool" is that every tool needs a hand.
AI Is a Mirror, Not a Mentor — What Actually Creates the Gap
Same model. Same input. Same output. Two completely different verdicts. The difference is not in the model. The difference is in the evaluator. Cleanly stated, the gap comes from four places.
- Presence vs absence of a judgment baseline: With no evaluation criteria, plausibility equals accuracy. With criteria, the two split apart.
- Signal for catching hallucination: Experts sense "this is wrong" instantly. Non-experts see only the fluency of the sentence.
- Context interpretation gap: AI sees context as words. Humans see context as meaning. That gap decides whether the same answer is right or wrong.
- Awareness of knowledge cutoff: The model knows nothing after its training cutoff. Without knowing this, you get confidently wrong guidance on new medical protocols, fresh case law, and the latest product specs.
All of this converges on one idea: the user's metacognition. AI is the examination table for that metacognition. Without an examiner, the exam is meaningless.
AI Is a Multiplier — How to Pull 10x From a Tool in the Field You Know
Now to the point. AI is not a substitute. It is a multiplier. If the user is at zero, the output is zero. If the user is at ten, AI pulls thirty, fifty, sometimes a hundred. The gap is made by four habits.
1. A prompt is a constraint, not a request
"Write me marketing copy" is the start of low-quality output. "B2B SaaS, IT decision-maker audience, under 100 words, avoid these three banned phrases, include one quantitative metric from a real customer review" — the moment you impose constraints, the output becomes ten times tighter. Constraints are the delegation of judgment.
2. The output is a draft, not an answer
Out of every 1,000 characters AI generates, you need to keep 200 and throw away 800. The person who knows which 800 to cut is the one really using AI. Someone who passes the whole thing through is using a compass to draw a circle.
3. A hallucination-check loop is not optional
Citations, numbers, statutes, names, dates — every factual claim must be cross-checked against the source. AI emits "plausible lies" with a perfectly straight face. Without a routine to catch them, AI output becomes poison that quietly corrodes the organization's trust.
4. Knowing the field lets you choose the tool
Code review is one model's strength. Copywriting is another's. The frame "AI is all the same" only breaks when you actually know a domain. Once you do, comparison becomes possible, and tool selection becomes precise.
Safety Guardrails in Unknown Territory — How to Use AI When You Can't Evaluate It
There are times when you have to use AI in a field you don't know. To avoid damage, three guardrails are non-negotiable.
- Force primary-source disclosure: Tell the model explicitly: "Exclude any claim that has no source." Hallucinations still slip through, but at least you get a starting point to verify.
- Cross-verify across models: Send the same question to a second model in a different framing. If the answers diverge, treat both as suspect.
- Route to a human expert for anything with a decision threshold: Medical, legal, accounting, contractual — anything with stakes. AI drafts. The human decides.
Using AI in an unknown field is safer when you treat it as a well-organized search engine plus a draft generator — not as a PhD you are consulting.
Implications for Leaders and Organizations — AI Adoption Is a Capability Audit, Not a Tool Purchase
Apply this principle to an organization and a hard conclusion follows. AI adoption is not "buying a tool." It is "diagnosing the distribution of judgment inside the organization." If the organization has weak judgment, AI adoption does not fix it. The volume of output multiplies. The volume of confidently wrong decisions multiplies with it. Speed goes up. Accuracy goes down.
The opposite is true for organizations with strong judgment. They use AI as a multiplier: one person's deep review is branched into ten variants, a human evaluates the variants, and the result converges into one sharpened decision. Speed and accuracy rise together. The real battle in AI adoption is not the model. It is the average capability of the user pool.
So before asking "should we buy another AI tool next quarter?", the right question is "can our team evaluate AI output?" Then the tool follows.
Conclusion — The Person Using AI Is Not a User. They Are a Judge.
Back to the lunch table. "AI is depressing in my own field." That is not a complaint. It is a fact. And read in reverse, it is hope. Knowing your field means you can use AI properly. And for fields you don't know, the right posture is still "I don't know — but I will evaluate before I act."
AI is not a PhD. It is a mirror. It reflects your judgment back at you. And — to say it bluntly — in front of someone with no judgment at all, it is a confident liar.
The gap between people who use AI well and people who use it poorly is not model literacy. It is the habit of constantly auditing your own metacognition. That habit is the actual competitive edge of the AI era. The tools are equally good. The variable is the operator.
Frequently Asked Questions
Q1. So to use AI well, I have to be an expert in everything?
No. You do need the minimum metacognition to evaluate the output: source-checking, fact-verification, the instinct to doubt. That minimum is what allows you to call a polished lie a lie.
Q2. Should I just avoid AI in fields I don't know?
For drafts, terminology, and outlines — outputs you can verify — AI is genuinely useful. For decisions, contracts, and medical/legal review, AI is a drafter only. The human reviewer is still mandatory.
Q3. As AI improves, will this problem go away?
Hallucination and context limits shrink with model quality. The cognitive bias of "trusting plausible fluency when you don't know better" is independent of the model. The tool gets better. The trap remains.
Q4. What should an organization invest in first?
Before tool budgets, invest in the user pool's evaluation capability. Prompt training, hallucination-verification workflows, mandatory review stages on AI output. These three investments return more than the next model upgrade.
Related posts
Read →Related tools